I was working on a data recast process which involves applying some complex mappings to the source data before it can be loaded to the target cube. This is quite a common exercise in applications related to Essbase, Planning and HFM.
I used a database to hold all those mappings along with the source data. I would recommend this approach as you have full control on what mapping you are applying and you can keep track of what mapping changes you are doing since the data recast process is a repeatable process
After the mappings have been applied, I had to do some manual addition of few accounts subtract data from few accounts. I am not an expert in SQL so excel pivot table to the rescue. All good and the data is ready to be loaded to the cube
Tip #1: Standardization is the key
Always use a standard load rule and a standard data load format for the data file (sort the columns from least to most and the dense dimension at the last and for columns). Also, use a standard delimiter in the rule file to prevent future modifications.
Tip #2: Header is the identity
Have a header record to identify the dimension for the column. The dimension is identifiable if it has prefixes. Otherwise, always have a header record
Tip #3: Know your data first
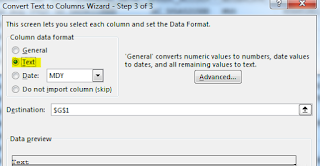
Often I get request from my friends and others (somehow they reach out to me through a common list of friends) that they get the error"Essbase encountered a field in the data source that it did not recognize". This generally happens when you have a number in a member column whereas essbase excepts a member name. There are instances where the member name is actually a number and when you use excel to do some transformation, excel converts the number to exponential format 1e+10. when you import the data to excel / transform the data using "Text to Columns", define the column data format as "Text" as shown below
Refer to the error document here for the list of possible error messages that you might encounter
Tip #4: Special characters are not special
If you have special characters in your member names, ensure that the delimiter in the rule file is not one among those special characters. If you have spaces in your member names, ensure that you have quotes surrounded like "Opening Inventory" and your delimiter is not SPACE. If you are saving the file as a csv and your member name has "," then follow the same principle as above for SPACES.
Tip #5: Avoid Copy Paste
Do not copy the data from Excel to file and update the delimiter.
All the above tips acts as a checkpoint to ensure that you have a repeatable process and following a standard methodology. (I have used a relational database to store the mapping. It's not mandatory to have a database. Whatever process you are comfortable with works. Ensure that you don't change the process each time you have to run the mapping and load the data again). Have a broader vision on how the process can be replicated for any future data recast processes. I do not have access to ODI / FMDEE which is another option but time consuming.
I was all set to get the data out and have the right delimiter set. Got the data out of the excel, loaded to the cube and started validation. Data doesn't tie.But, data doesn't lie. Where did it go wrong?
Tip #6: Data doesn't lie
(Recommended for small data sets). Validation always happen at the top level. Since, ours an ASO cube, I don't have to run any aggregations. I love ASO. I really love ASO (Awesome Storage Option :) ). I quickly copied the data file in to excel, added the missing members in the file and tadaaaaa. I realized what went wrong. I was loading data to 5 periods ( 4 periods and BegBal) and the BegBal column was completely empty and the load rule shifted the other 4 period columns to left. Q1 data got loaded to BegBal, Q2 to Q1 and so on. I added #Mi in the BegBal column and all good
Happy learnung
I used a database to hold all those mappings along with the source data. I would recommend this approach as you have full control on what mapping you are applying and you can keep track of what mapping changes you are doing since the data recast process is a repeatable process
After the mappings have been applied, I had to do some manual addition of few accounts subtract data from few accounts. I am not an expert in SQL so excel pivot table to the rescue. All good and the data is ready to be loaded to the cube
Tip #1: Standardization is the key
Always use a standard load rule and a standard data load format for the data file (sort the columns from least to most and the dense dimension at the last and for columns). Also, use a standard delimiter in the rule file to prevent future modifications.
Tip #2: Header is the identity
Have a header record to identify the dimension for the column. The dimension is identifiable if it has prefixes. Otherwise, always have a header record
Tip #3: Know your data first
Often I get request from my friends and others (somehow they reach out to me through a common list of friends) that they get the error"Essbase encountered a field in the data source that it did not recognize". This generally happens when you have a number in a member column whereas essbase excepts a member name. There are instances where the member name is actually a number and when you use excel to do some transformation, excel converts the number to exponential format 1e+10. when you import the data to excel / transform the data using "Text to Columns", define the column data format as "Text" as shown below

Refer to the error document here for the list of possible error messages that you might encounter
Tip #4: Special characters are not special
If you have special characters in your member names, ensure that the delimiter in the rule file is not one among those special characters. If you have spaces in your member names, ensure that you have quotes surrounded like "Opening Inventory" and your delimiter is not SPACE. If you are saving the file as a csv and your member name has "," then follow the same principle as above for SPACES.
Tip #5: Avoid Copy Paste
Do not copy the data from Excel to file and update the delimiter.
All the above tips acts as a checkpoint to ensure that you have a repeatable process and following a standard methodology. (I have used a relational database to store the mapping. It's not mandatory to have a database. Whatever process you are comfortable with works. Ensure that you don't change the process each time you have to run the mapping and load the data again). Have a broader vision on how the process can be replicated for any future data recast processes. I do not have access to ODI / FMDEE which is another option but time consuming.
I was all set to get the data out and have the right delimiter set. Got the data out of the excel, loaded to the cube and started validation. Data doesn't tie.But, data doesn't lie. Where did it go wrong?
Tip #6: Data doesn't lie
(Recommended for small data sets). Validation always happen at the top level. Since, ours an ASO cube, I don't have to run any aggregations. I love ASO. I really love ASO (Awesome Storage Option :) ). I quickly copied the data file in to excel, added the missing members in the file and tadaaaaa. I realized what went wrong. I was loading data to 5 periods ( 4 periods and BegBal) and the BegBal column was completely empty and the load rule shifted the other 4 period columns to left. Q1 data got loaded to BegBal, Q2 to Q1 and so on. I added #Mi in the BegBal column and all good
This is due to the violation of Rule #5That's all I have for today. Let me know if you have any more tips to add. You can post in the comments and i will add them as updates to this blog post
Happy learnung
I like reading the above article because it clearly explains everything and is both entertaining and effective. Thank you for your time and consideration, and best of luck with your future articles.
ReplyDeleteData Engineering Solutions
Artificial Intelligence Services
Data Analytics Services
Data Modernization Services